Оригинал: ‘Django migrations without downtimes’ by Ludwig Hähne
Большинство современных веб-приложений используют реляционные базы данных. Время от времени в них приходится менять схему для реализации новых фич или удаления ставших ненужными полей или таблиц. Так что все миграции должны быть учтены в процессе деплоя. С одной стороны, даже запланированный даунтайм может дорого обойтись бизнесу, а уж для больших компаний и подавно. С другой стороны, применение миграций на боевой системе может порушить веб-приложение самым неожиданным образом. Речь пойдёт о самых распространённых сценариях изменений на примере postgresql. Мы рассмотрим блокирующие и временные проблемы, многоходовки при деплое, а также особенности миграций.
Введение 🔗
Миграции баз данных - основная проблема при реализации процесса непрерывного деплоя без простоя веб-приложений. Со временем у нас появляются новые скрипты для облегчения этого процесса, но всё равно пока что это небезопасная операция. Распространены два подхода к миграциям. Один из них - оптимистичный - заключается в применении прям на боевом сервере, при этом все молятся. Но это помогает не всегда, и однажды что-то ломается. Это нам не подходит. Если скил молитвы у вас не прокачен, то рано или поздно придётся использовать пессимистичный подход: выделять время для каждой миграции. Никаких неожиданных блокировок не будет, потому что сервера будут исключены из обслуживания. Это не очень нравится клиентам, так что время даунтайма надо выбирать с осторожностью и заранее об этом всех уведомлять. Конечно, я утрирую, но хочу подчеркнуть, что ни один из подходов не является идеальным. Так что разработчики по мере возможностей стараются не трогать схему базы данных. Из-за этого рождаются костыли и странные решения. Понимание возможных проблем при миграциях должно помочь избежать неожиданных падений и простоев, а также помочь откатить данные до их изначального состояния.
Сценарии 🔗
Рассмотрим самые популярные сценарии миграций на примере Django >= 1.7 (там наконец-то появился встроенный механизм) и PostgreSQL в качестве базы данных.
Добавление таблицы 🔗
Самый простой случай - добавление таблицы, так как никто не будет даже пытаться с ней работать. Единственно надо убедиться, что она создалась раньше, чем был обновлён код. Ниже приведена небольшая иллюстрация, где на примере одной базы данных и 3х серверов приложений рассмотрен данный сценарий.
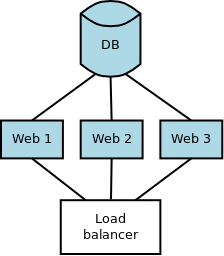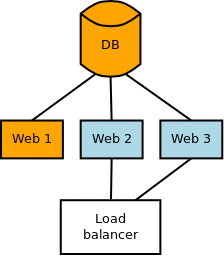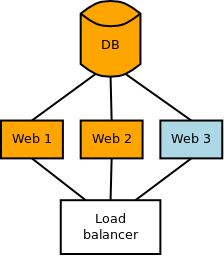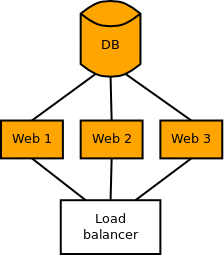
Если вы применяете миграции с сервера приложений, то это легко автоматизировать:
- исключить сервер из балансировщика нагрузки
- развернуть новый код на сервере
- запустить миграции
- включить сервер в балансировщик нагрузки
Так как миграции Django иденпотентны, то их последовательный (и только последовательный!) запуск безопасен. Однако, не все миграции могут быть применены перед запуском обновлённого кода, что мы рассмотрим ниже на примере удаления колонки.
Добавление колонки 🔗
Добавление колонки в существующую таблицу также довольно распространённая операция, но о её сложности можно судить по нескольким факторам:
Блокировки 🔗
При добавлении столбца вы неявно выполняете блокировку всей таблицы. Если в этот момент кто-то работает с ней, то инструкция ALTER TABLE будет заблокирована до окончания выполнения всех существующих запросов. Но на время выполнения команды по миграции схемы никакая другая работа с таблицей будет невозможна.
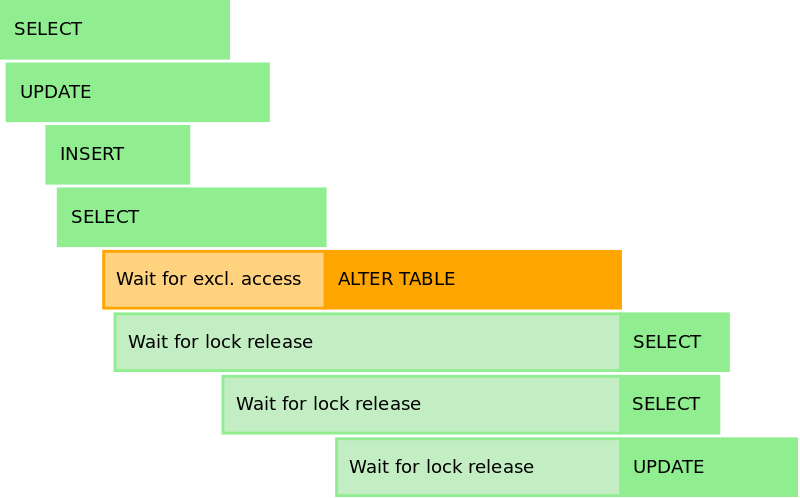
В postgresql все блокирующие запросы ставятся в обычную FIFO очередь без приоритетов. Так что даже последовательное чтение может отложить выполнение ALTER TABLE (как-то странно звучит?). Это означает, что вы должны побеспокоиться не только о продолжительности миграции, но также и о продолжительности запросов, которые могут быть запущены во время её применения. Иными словами - если у вас есть каки-либо сторонние сервисы с медленными запросами, то лучше их на время приостановить.
Транзакции 🔗
К счастью, postgresql поддерживает транзакционнный DDL. Текущие версии Django оборачивают каждую миграцию в свою транзакцию, так что часть базы данных блокируется на время выполнения миграции. То есть если у вас есть множество несвязанных между собой инструкций, то лучше их выполнять по отдельности - каждую в своей транзакции, чтобы избежать блокировок тех объектов, которые уже не нужны и уменьшить риск клинчев.
Перезаписи таблиц 🔗
Приведённый выше рисунок показывает важность длительности выполнения миграции, так как все остальные запросы будут ждать освобождения ресурсов. При добавлении столбцов со значением по умолчанию Postgres пробежится по всей таблице и вычислит значение для каждой строки. Это может быть не быстро, если данных много, т.к. реализация редактирования записи сводится к её копированию и вставке уже изменённой. Согласно документации, добавление nullable столбца не приводит к полной перезаписи таблицы.
NULL или NOT NULL 🔗
Можно объявить все поля как nullable и избежать многих проблем при миграциях, однако у такого подхода есть и свои недостатки. Пока вы работаете с отдельными объектами всё выглядит неплохо, однако надо быть осторожным при использовании фильтров:
if not user.blocked:
# Works with `False` and `NULL`
User.objects.filter(blocked=False) # XXX
User.objects.filter(~Q(blocked=True))
User.objects.exclude(blocked=True)
Значения по умолчанию 🔗
Django весьма своеволен при работе с базой данных, и есть одна вещь, которую надо постоянно держать в уме - значения по умолчанию. Они не устанавливаются в базе данных - за ними следит Django. Да-да, то есть при записи новой строки он пробегается по всем null полям и вычисляет значение по умолчанию, если оно указано. Об этом постоянно надо помнить, т. к. после миграции попытка записи из старого приложения будет приводить к ошибке - в это поле будет вставлятся по умолчанию null, что может не соответствовать ограничениям.
Сказать Django не игнорировать значение по умолчанию не так-то просто, Приходится дописывать свой RunSQL для его установки на уровне базы данных.
RunSQL(
'ALTER TABLE users ADD COLUMN blocked BOOLEAN NOT NULL DEFAULT false',
'ALTER TABLE users DROP COLUMN blocked',
state_operations=[
migrations.AddField(
model_name='users',
name='blocked',
field=models.BooleanField(default=False),
preserve_default=True,
),
],
)
Пример: добавление булевого поля 🔗
Допустим, вам нужно добавить в большую таблицу булево поле со значением по умолчанию False. При применении на стейдже легко заметить, что BooleanField(default=False) будет выполняться очень долго, и разумным выходом кажется изменить на NullBooleanField(default=False).
django-admin sqlmigrate покажет нам следующее:
BEGIN;
ALTER TABLE users ADD COLUMN blocked BOOLEAN DEFAULT false NULL;
ALTER TABLE users ALTER COLUMN blocked DROP DEFAULT;
COMMIT;
Попробуйте выполнить этот блок в psql с включённым \timing, и увидите, что ADD COLUMN приводит к перезаписи всей таблицы (т.к. меняется каждая запись). Вы можете разбить миграцию:
- добавить поле как nullable без значения по умолчанию
migrations.AddField(
model_name='user',
name='blocked',
field=models.NullBooleanField(),
preserve_default=True,
)
это приведёт к блокировке таблицы, но полной перезаписи не будет
- добавить значение по умолчанию
RunSQL(
'ALTER TABLE users ALTER COLUMN blocked SET DEFAULT false',
'ALTER TABLE users ALTER COLUMN blocked DROP DEFAULT',
state_operations=[
migrations.AlterField(
model_name='user',
name='blocked',
field=models.NullBooleanField(default=False),
preserve_default=True,
)
],
)
добавление значения по умолчанию также не приводит к перезаписи
- обновить существующие строки
пакетное редактирование записей в миграции несколько неочевидно, т.к. вы рискуете поломать транзакцию, в которой запущена миграция. Можно использовать такой грязный хак-декоратор для функции в RunPython:
def non_atomic_migration(func):
@wraps(func)
def wrapper(apps, schema_editor):
if schema_editor.connection.in_atomic_block:
schema_editor.atomic.__exit__(None, None, None)
return func(apps, schema_editor)
return wrapper
Всё вместе будет выглядеть как-то так:
BATCHSIZE = 1000
@non_atomic_migration
def initialize_data(apps, schema_editor):
User = apps.get_model("user", "User")
max_pk = User.objects.aggregate(Max('pk'))['pk__max']
if max_pk is not None:
for offset in range(0, max_pk+1, BATCHSIZE):
(User
.filter(pk__gte=offset)
.filter(pk__lt=offset+BATCHSIZE)
.filter(blocked__isnull=True)
.update(blocked=False))
class Migration(migrations.Migration):
operations = [
migrations.RunPython(initialize_data, atomic=False),
]
Надеюсь, в следующих версиях Django обдумают эту проблему. (От переводчика: вообще-то у каждой операции есть свойство atomic - можно им воспользоваться)
- добавить ограничение not null
migrations.AlterField(
model_name='user',
name='blocked',
field=models.BooleanField(default=False),
preserve_default=True,
)
и снова полного обновления записей не будет.
Удаление таблицы или столбца 🔗
Само удаление таблицы или столбца не должно вызывать трудностей, однако есть маленкий нюанс - вам нужно применить миграцию после того, как код на всех серверах обновлён. Будьте осторожны, если удаляемый столбец имеет ограничение not null и не имеет значения по умолчанию в БД. В таком случае операция INSERT из нового кода будет валиться до применения миграции. В таком случае можно отменить ограничение или задать какое-нибудь значение по умолчанию. Если миграции выполняются в автоматическом режиме, то следует разделить на 2 этапа: сначала удалить поле из модели и снять NOT NULL ограничение, а лишь после того, как код везде будет обновлён, удалить сам столбец.
Работа с данными 🔗
Итак, мы рассмотрели добавление и удаление функциональности, но самое интересное когда меняется назначение уже существующих полей, и данные там надо как-то модифицировать. Для начала обратимся к примеру из документации Django, в котором поля для имении и фамилии сливаются в одно. Давайте предположим, что вы примените миграцию во время работы приложения. Будет создан новый столбец и заполнен вычисленными данными, однако работающий в это время старый код (назовём его V1) будет добавлять записи в старом формате. И только после деплоя нового кода (V2) на все сервера, приложение заработает целиком по новой схеме. Отсюда возникает несколько проблем, связанных с работой через V1:
- пользователи добавляют новые записи - и это поле остаётся пустым
- пользователи редактируют уже модифицированные записи - и это поле становится противоречивым
Самым простым будет перезапустить миграцию после того, как V2 развёрнут на всех серверах. Тем не менее, если не следить какая запись какой версией программы изменяется, то вы можете потерять обновления, сделанные через V2, из-за перезаписи старыми данными. Другим вариантом будет создание промежуточного кода, который будет сочетать в себе как старую, так и новую логику:
def set_name(person, name):
person.name = name
person.first_name, person.last_name = name.rsplit(' ', 1)
person.save()
Если закрыть глаза на не самую лучшую реализацию разделения имени, то это подход может сработать. Достаточно просто убедиться, что миграция прошла для всех записей после деплоя такого промежуточного кода. Однако, такой подход может оказаться довольно сложным, если вам надо следить за работой с данными более чем в паре мест. Чтобы сосредоточить всю логику в одном месте можно воспользоваться pre-save сигналом модели, однако следует помнить, что они не вызываются при пакетном обновлении. Если эта проблема всё ещё актуальна для вас, то придётся обратиться к триггерам на уровне базы данных:
CREATE OR REPLACE FUNCTION update_person_name() RETURNS trigger AS $func$
BEGIN
IF NEW.first_name IS NULL THEN
NEW.first_name = split_part(NEW.name, ' ', 1);
NEW.last_name = split_part(NEW.name, ' ', 2);
END IF;
RETURN NEW;
END;
$func$ LANGUAGE plpgsql;
CREATE TRIGGER on_person_update
BEFORE INSERT OR UPDATE ON person
FOR EACH ROW
EXECUTE PROCEDURE update_person_name();
Недостатком является то, что их трудно обновлять, их возможности сильно ограничены, про них часто забывают в конце концов. Однако, когла выкатываются сложные изменения, то это будет самым простым и надёжным решением. Не забудьте только их удалить после того, как они станут не нужны.
Подводя итоги 🔗
Помио избежания ненужного простоя в работе есть ряд преимуществ при выполнения онлайн миграций:
- возможность быстрого отката
- позволяет поэтапно разворачивать приложения по серверам
Есть и ряд минусов:
- повышается сложность
- БД проходит через несколько промежуточных состояний
- если что-то свалилось по середине, то откат может быть нетривиален
Если вы знаете что делаете, или если вы работаете в компании, у которой в SLA очень много девяток, то можете запускать все миграции на боевом сервере. Чем больше изменений будет в миграциях, тем больше возможных состояний будут проходить данные, в результате чего вы будете получать ошибки во всё более непонятных ситуациях. Начиная с какого-то уровня сложности, попытки избежать простоя будут стоить компании больше, чем сам простой. Может, в таком случае проще потерпеть гневные крики пользователей минут 10? :) Тем не менее, некоторые изменения могут быть безопасно применены к работающей базе при соблюдении ряда условий:
- добавлять nullable столбец для больших таблиц
- при добавлении NOT NULL добавлять вручную и значение по умолчанию
- делать маленькие миграции
- вызывать sqlmigrate чтобы понимать что на самом деле будет выполняться в базе данных
- замерять время выполнения на стейдж-сервере
- временно приостановить работы сторонних сервисов, которым нужны изменяемые таблицы
- пакетно редактировать записи в небольших транзакциях
Пожелания для Django 🔗
Хотелось бы добавить ряд пожеланий для разработчиков Django, чтобы упростить создание и применение миграций:
- возможность объявлять миграцию как не атомарную
- задачать значения по умолчанию на уровне БД
- добавить возможность выполнять код после миграции или блокировать некоторый код на время выполнения
Заключение 🔗
Надеюсь, пост оказался полезным. Если у вас есть замечания или дополнения, заведите баг на GitHub или напишите в Twitter.