Давеча разгорелся спор на работе по поводу того как вести историю изменений. Поводом послужила вот такая картина:
В hg есть 2 способа слить 2 ветки — merge и rebase. Про merge знают даже svnщики, а вот rebase появился только в DCVS. Смысл его заключается в том, чтобы перенести корень ветки в другое место. Например:
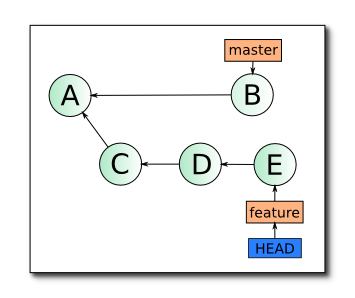
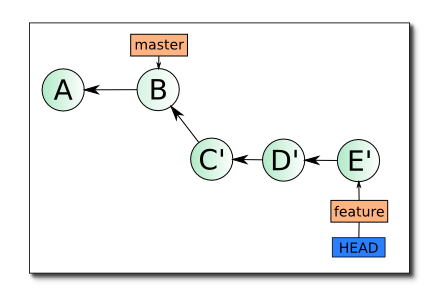
То есть не к A будут применяться диффы feature-ветки, а к B. Замечу, что C != C. Это разные диффы! (Подробно механизм описан в этой статье) Но цель достигнута — лишняя сущность в виде ветки ушла. Оккам восторжествовал, а мне стало проще читать коммиты. Надеюсь, никто не станет спорить, что линейная история читается проще веток 🙂
Итак, инструмент для слияния есть. В чём же его плюсы? Думаю, только в удобной истории. Всего лишь? Да. Мало? Нет! Ретроспективно анализировать код порой очень сложно, а лишние мерджи только усложняют ситуацию. А ты вот сидишь и думаешь «Что же автор хотел этим сказать???». Так что когда много мелких изменений от разных авторов лучше воспользоваться всё-таки rebase 🙂 Сейчас-то разницы особой нет, а вот лет через 5, когда некоторые разработчики уйдут, тогда будет бо-бо 🙂 Кстати, линейная история позволяет проще работать с git-bisect (это так уже, плюшка).
Что меня больше всего поразило, так это мерджи с заголовком «Automated merge …». Их создал SourceTree автоматически. Для меня коммит сродни некоему высказыванию. Я стараюсь говорить только по делу (одна задача - один коммит). А тут клиент hg что-то говорит за меня да ещё и то, что мне не нравится. Благо можно выставить настройку чтобы вместо merge делался rebase. Да и коммиты порой squash’ить надо бы.
А когда ж следует использовать привычный всем merge? Мне видятся несколько ситуаций:
- feature-ветка — необходимо сохранить историю создания какой-либо функциональности;
- критичность времени коммита — при rebase, насколько я понял, новым коммитам проставляется текущая дата. Мне как-то всё равно, но мало ли для кого это принципиально.
- ветка с коммитами C, D, E уже запушена — никогда не редактируйте запушенную ветку. Этим Вы отменяете текущие коммиты и создаёте новые, которые похожи на оригинал, но всё же другие. Коллеги возненавидят Вас, так как им придётся заново сливать изменения.
- не тривиальный мердж.
В остальных случаях рекомендую воспользоваться rebase. И да будут Ваши коммиты красивыми, а история понятной 🙂
P.S. Для знающих английский рекомендую к прочтению ещё и эту статью.
Upd. Раз уж заговорили про rebase, то стоит упомянуть и практическое применение. Бывают ситуации, когда ветка выросла не оттуда. Например, хотфикс пошёл от develop, а не от master. А узнаёте вы об этом только перед релизом… Что ж, ничего страшного - надо всего лишь пересадить всю ветку на другой коммит.
$ git rebase --onto <куда> <начальный коммит~1> <последний коммит>
Вот и всё - диапазон коммитов <начальный коммит>..<последний коммит> перемещён на другой источник. Один момент - после этих действий вы находитесь в состоянии detached HEAD (то есть с текущим коммитом не связана ни одна ветка). Достаточно всего лишь подвинуть метку ветки на него:
$ git branch -f <имя ветки> <коммит, на котором стоите>
Upd 2. Пришлось поработать с проектом, на котором мердж пулл реквестов происходит с --squash. И это ад!
Во-первых, вы теряете информацию как именно разрабатывалась фича. Например, почему код находится именно в этом месте, хотя логично было бы его расположить в другом модуле? В случае без сквоша, вы через blame найдёте последний коммит, который менял этот код, и увидите, что раньше он был на логичном месте; а в комментарии к коммиту что-нибудь типа “Move function … because …”.
Во-вторых, Вы получаете коммит +700, -350. Вы действительно думаете, что поймёте что там происходит спустя год?
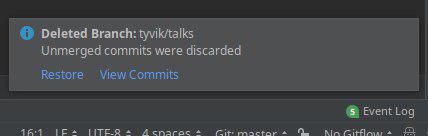
В-третьих, вы перетираете историю. А это значит, что при удалении локальной ветки после мерджа на GitHub, вы увидите вот такую картину: