Что такое SaaS и тенант? 🔗
Sofware as a Service (SaaS) - модель реализации вашего приложения, когда вы предоставляете свой продукт разным клиентам практически не меняя его. Например, есть у вас CRM, и вы подключаете в неё нескольких клиентов, разнося их по поддоменам: mvideo.crm.ru, dns.crm.ru, eldorado.crm.ru… Код процентов на 90% совпадает, различаются лишь стили и третьестепенная бизнес-логика. Каждый клиент в этом случае завётся тенантом. А чтобы чуть упростить вашу жизнь как разработчика, познакомлю с такой классной вещью как мультитенантность на примере DjangoORM и PostgreSQL.
Модели реализации 🔗
Итак, у нас есть некоторый продукт, который разрабатывался для одного заказчика. В общем случае он состоит из сервера приложений и базы данных. Потом ваше начальство заметило, что его же почти без переделок можно продать ещё нескольким клиентам. В случае, если у вас уже реализована какая-либо оркестрация, то скорее всего проще будет развернуть рядом ещё один кластер k8s или Docker Swarm. Это вполне рабочее решение, которое успешно масштабируется. Да, будут накладные расходы на поддержание окружений в едином состоянии и одной версии, но иногда это вполне допустимо.
Однако, т.к. клиент у вас один, то скорее всего проект молодой, и никто никакой оркестрации ещё не успел ввести. Так что добавляем колонку client_id во все таблицы с общими данными и приглашаем второго клиента пользоваться нашим продуктом. Не забываем пройтись по всем запросам и добавить фильтрацию по client_id, а то будет возможность заглянуть в чужие данные. Я тоже когда-то пошёл по этому пути. На 10 редактировании мне показалось странным такое количество копипасты, на 50 я понял, что это путь в никуда - должно быть более лёгкое решение без дублирования кода. Хочется раз настроить, и чтобы оно работало само… И об этом чуть дальше.
Первые проблемы 🔗
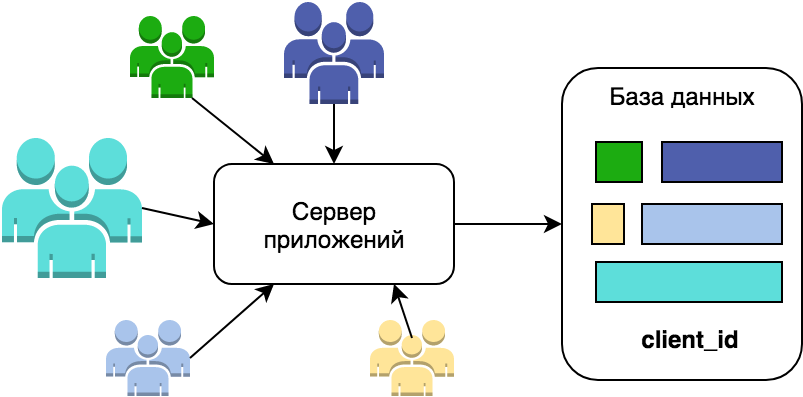
Реализация шардирования 🔗
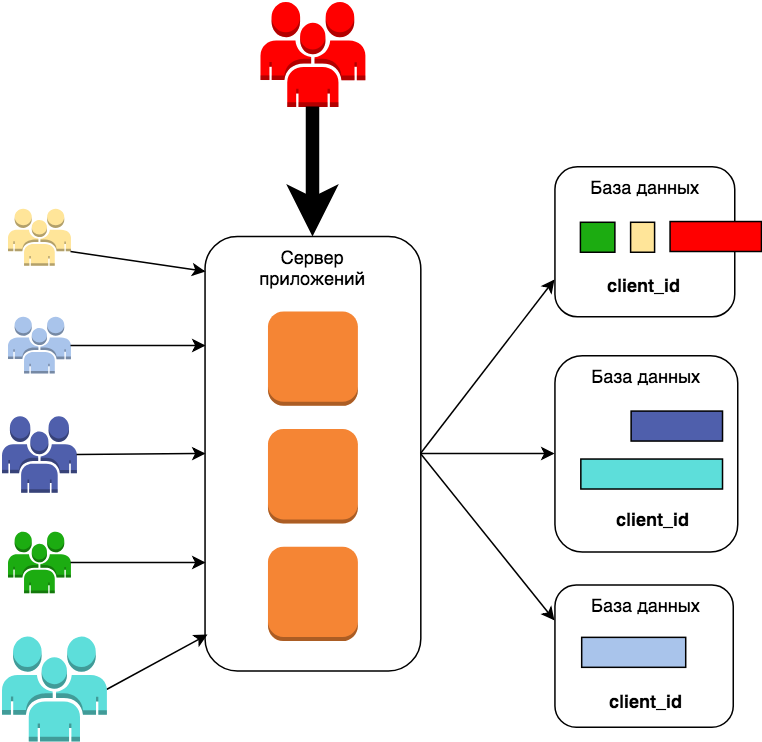
Но потом приходит жирный клиент, садится в первую базу данных, и она умирает вместе с зелёным с жёлтым клиентами. Они будут не очень этому рады. Тут скорее всего надо будет правильно подобрать ключ шардирования, чтобы добавить нового большого клиента на отдельный сервер, не затронув работу остальных. Мне кажется, что в общем случае это можно будет сделать только вручную, но это не наш путь. Регистрация нового клиента должна быть автоматическая и занимать пару минут. Так что двигаемся дальше.
Схема мультитенантности 🔗
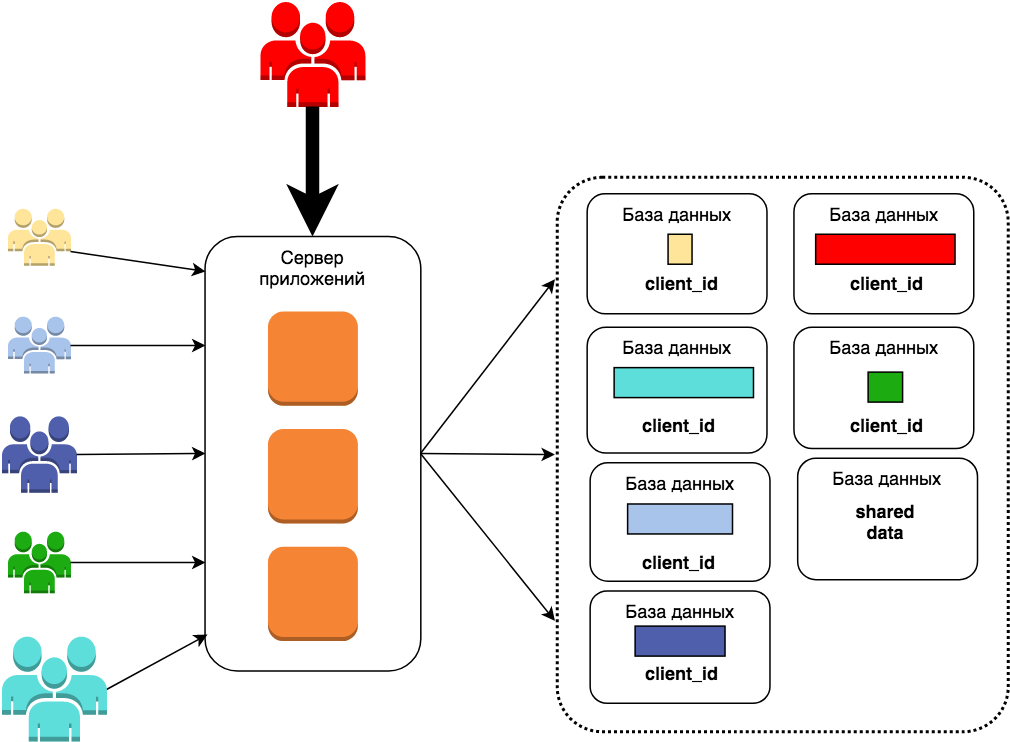
Это и есть мультитенантность. Организация работы, при которой выполняется общий код, но все данные клиентов изолированы друг от друга. Такое поведение можно реализовать и на Java, и на C#, и на Oracle, и на MySQL - это всего лишь идея, паттерн. Вам не кажется, что здесь всё равно есть нечто лишнее? Столбец client_id уже не нужен, т.к. он будет принимать единственное значение для каждой БД. Его можно смело выкинуть или перенести id клиента в название бд.
У этой схемы есть ряд плюсов:
- Полная изоляция данных клиента друг от друга. То есть не надо помнить, что каждый запрос к их данным надо ограничивать также и по client_id.
- Проще менеджить каждого отдельного клиента. Делать бекап именно его БД.
- Можно точно посчитать сколько у клиента суммарно данных, а также какую мощность сервера БД он потребляет. Ну и выставить в зависимости от них разный счёт.
- У вас одно приложение и одна кодовая база, а это значит, что и обновлять его будет проще, нежели инсталляцию под каждого клиента.
- Возможность масштабирования в дальнейшем.
Из минусов:
- Сложность. Необходимо маршрутизировать запросы одного клиента в одну схему, другого - в другую.
- Теряется ссылочная целостность между общими справочниками и данными клиента. Там теперь вместо ссылки просто int значение. Но, к слову, это не так страшно потому как можно значения из них продублировать в каждой базе клиента и поддерживать консистентность через миграции. Это если пользователи сами не могут заполнять эти справочники.
- Увеличится пул соединений Django с разными инстансами Postgres. Если у вас k инстансов приложений и n клиентов (и они разделены по схемам), то будет k*n соединений к БД. На небольших объёмах это не страшно, но может быть проблемой в дальнейшем.
Уровни изоляции данных клиентов 🔗
Теперь, когда общая схема понятна, подумаем над реализацией. Первое, что необходимо выбрать - уровень изоляции. Всего их возможно 3:
- общая БД, общие таблицы. Данные всех клиентов хранятся в одной таблице и разделяются лишь на уровне логики приложения. Какой-либо изоляцией здесь и не пахнет.
- общая БД, по схеме на клиента. Самый простой и в то же время наиболее востребованный - на уровне схем в единой базе данных.
- отдельная БД на клиента. Будь то БД в докере или даже отдельная RDS. И единственный способ для MySQL, т.к. там отсутствет понятие схемы.
Самым популярным является второй уровень, его реализуют сразу несколько библиотек под django (я оставил лишь те, которые обновлялись за последний год): django-tenant-schemas, django-tenants, django-multitenant, django-boardinghouse, django-pgschemas. Обратите внимание - почти все они упоминают PostgreSQL, т.к. работают со схемами, а не с базами данных. Лично я работал с django-tenant-schemas. Каких-то проблем я там не помню, она самая популярная, так что советую начать смотреть именно с неё. У django-boardinghouse несколько иная концепция разделения таблиц (вернее API), кому-то будет удобнее такая настройка. В любом случае у неё хорошая концептуальная документация, стоит почитать.
Собственная реализация 🔗
Для того, чтобы понимать как уже готовые библиотеки работают под капотом, я люблю делать свои велосипеды и сразу же их выбрасывать. Давайте попробуем реализовать минимально необходимый для приложения функционал.
Сначала рассмотрим как Django работает с базами данных. При старте читается заветный словарик DATABASES из settings.py. Там описаны все доступные приложению базы данных. Но запросы надо же как-то маршрутизировать - что-то отправить на реплику, что-то в SQLite или иные БД, с которыми работает приложение.
DATABASES = {
'default': {
'ENGINE': config.get('database', 'ENGINE'),
'NAME': config.get('database', 'NAME'),
'USER': config.get('database', 'USER'),
'PASSWORD': config.get('database', 'PASSWORD'),
'HOST': config.get('database', 'HOST'),
'PORT': config.get('database', 'PORT')
}
}
В Django есть несколько способов сделать это. Во-первых, использовать using() при построении каждого запроса через ORM.
Model.objects.filter(...).using(...)
Model.objects.filter(...).using(...)
Model.objects.filter(...).using(...)
...
Model.objects.filter(...).using(...)
Но это не наш путь - слишком много дублирования, всё должно быть автомагически. Так что воспользуемся вторым способом. В settings.py также определяется класс DATABASE_ROUTERS, который отвечает за это на более низком уровне. По модели и некоторым подсказкам он говорит куда направить запрос. Самое простое - добавить в модель какой-нибудь атрибут типа is_global, а вычислять нужную БД по id клиента.
class ClientDbRouter(object):
def db_for_read(self, model, **hints): ...
def db_for_write(self, model, **hint): ...
def allow_relation(self, obj1, obj2, **hints): ...
def allow_migrate(self, db, app_label, model_name=None, **hints): ...
Но, собственно, откуда этот самый id клиента брать? Ну раз у вас SaaS, то скорее всего клиенты висят на разных поддоменах, и вот по названию поддомена смотреть какой это клиент. Или при логине пользователя добавлять ключ в его сессию. Вот так:
class TenantMiddleware(MiddlewareMixin):
thread_local = threading.local()
def process_request(self, request):
client_id = request.user.client_id if request.user.is_authenticated else None
TenantMiddleware.thread_local.client_id = client_id
или вот так:
env = threading.local()
class TenantMiddleware(object):
def process_request(self, request):
account = None
if 'account_id' in request.session:
account = Account.objects.get(id=request.session['account_id'])
env.__dict__.update({
'context_account': account
})
На самом деле не важно как именно, главное - чтобы это значение было доступно из любой точки программы в процессе обработки запроса. Да, нужно положить id клиента в глобальную переменную процесса python. И для этого даже есть библиотечка django-threadlocals.
Окей, но в случае первого запроса нового клиента приложение упадёт, т.к. не найдёт подходящую БД. Напоминаю, что их список жёстко прописан в settings.py и неизменен в процессе выполнения приложения. Так давайте сделаем его динамическим, а именно классом, который прикидывается словарём:
class DynamicDatabaseMap(object):
def __init__(self, default):
self.data = {
'default': default
}
def __getitem__(self, item):
if item not in self.data:
self.load_db(item)
return self.data[item]
def __contains__(self, item):
return item in self.data
def __iter__(self):
return iter(self.data)
def load_db(self, name):
self.data[name] = {
'NAME': name,
'ENGINE': self.data['default']['ENGINE'],
'USER': self.data['default']['USER'],
'PASSWORD': self.data['default']['PASSWORD'],
'HOST': self.data['default']['HOST'],
'PORT': self.data['default']['PORT']
}
def keys(self):
return self.data.keys()
У нас остаётся база данных default - наша общая база, но в случае попытки доступа по несуществующему ключу в словарь добавляется описание для подходящей базы. Здесь предполагается, что все они хостятся на одном сервере, а меняется лишь имя БД. Причём эта база уже должна существовать. Так что следующий этап - её создание.
Я не буду подробно останавливаться на создании БД, лишь пройдусь по пунктам:
-
Подключиться к серверу Postgres через psycopg2, не используя ORM:
connection = psycopg2.connect(host=..., user=..., password=...) connection.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT) -
Создать через курсор новую базу. Причём я советую иметь некую пустую шаблонную базу для того, чтобы сократить время миграции:
cursor = connection.cursor() cursor.execute(f'CREATE DATABASE "{name}" OWNER "{user}" TEMPLATE "{init_db}"') -
Инициализировать её в роутере:
settings.DATABASES.load_db(self.get_database_name()) -
Запустить миграции, которых ещё нет в шаблонной базе:
call_command('migrate', database=self.get_database_name(), interactive=False, verbosity=0)
Всё, можно катить в прод! Шутка, ещё рано. Что если код выполняется вне контекста, то есть у нас нет запроса, нет домена и непонятно из какой бд читать? Например, задача celery или менеджмент команда.
Тут придётся использовать менеджер контекстов и явно в коде говорить для какого клиента должен быть выполнен следующий код:
class use_client(object):
def __init__(self, client_id):
self.client_id = client_id
self.previous_client = None
def __enter__(self):
self.previous_client = getattr(thread_local, 'client_id', None)
thread_local.client_id = self.client_id
def __exit__(self, exc_type, exc_val, exc_tb):
thread_local.client_id = self.previous_client
Не очень красиво, но что поделать. Внизу же пример использования в декораторе foreach_client, который проходит по всем клиентам и выполняет какую-то функцию. Например, миграции. Очень полезная вещь, скорее всего и у вас появится что-то похожее. Кстати, здесь пример упрощён, а вообще можно распараллелить этот процесс:
def foreach_client(func, *args, **kwargs):
from apps.accounts.models import Client
for client_id in Client.objects.values_list('id', flat=True):
with use_client(client_id):
return func(*args, **kwargs)
Это что касается работы с базой, но надо ж ещё корректно обновить ключи кеширования, обработку URL и тому подобное. Скорее всего кто-то это уже делал до меня, и лучше взять готовую библиотеку.
Заключение 🔗
Мультитенантность - всего лишь один из способов организации приложения со своими плюсами и минусами. Я ни в коем случае не призываю сразу же реализовывать на вашем проекте. Возможно, вам больше подойдёт Citus - расширение для Postgres, которое умеет шардироваться, подстраиваться под аналитические запросы и пр. Правда, я с ним не работал, ничего более сказать не могу. Разобранное решение хорошо работает на небольшом количестве клиентов, при росте надо будет вводить дополнительные костыли в виде, например, кластеризации клиентов, чтобы бороться уже с техническими ограничениями. Ну или переходить на другую схему работы - решать уже вам :)