Рано или поздно перед каждым разработчиком встаёт задача что-нибудь стянуть с какого-нибудь сайта :) На этот раз я улетал туда, где интернета не было, так что хотел получить некую оффлайновую копию информации с сайта. Сам я не поощряю такие вещи (всё-таки авторы приложили немало усилий для наполнения контентом), но один разочек исключительно для личных нужд можно :) В интернете есть куча библиотек для парсинга сайтов, но я бы хотел найти реализацию на питоне. Можно было самому писать обход страниц, логгирование, распараллеливание задач, генерирование заголовков HTTP запросов, модификацию информации, но я нашёл фреймворк, который большую часть работы делал за меня. Так я познакомился со Scrapy.
Пример будет несколько абстрактный - выгрузить в json файл названия статей вместе с именем автора, допустим, с Хабра. В реальной жизни у меня, конечно, совсем другая задача, но я бы не хотел выкладывать паука для сайта, к разработчикам которого испытваю большое уважение. Так что да простит меня Хабр :)
Сразу предупреждаю, что нет какого-либо универсального решения, потому что каждый сайт предоставляет информацию по-разному: например, генерацией целых страниц с сервера или ajax-пагинацией; в div или в table… Так что первое, что нужно сделать - изучить структуру сайта с помощью консоли разработчика.
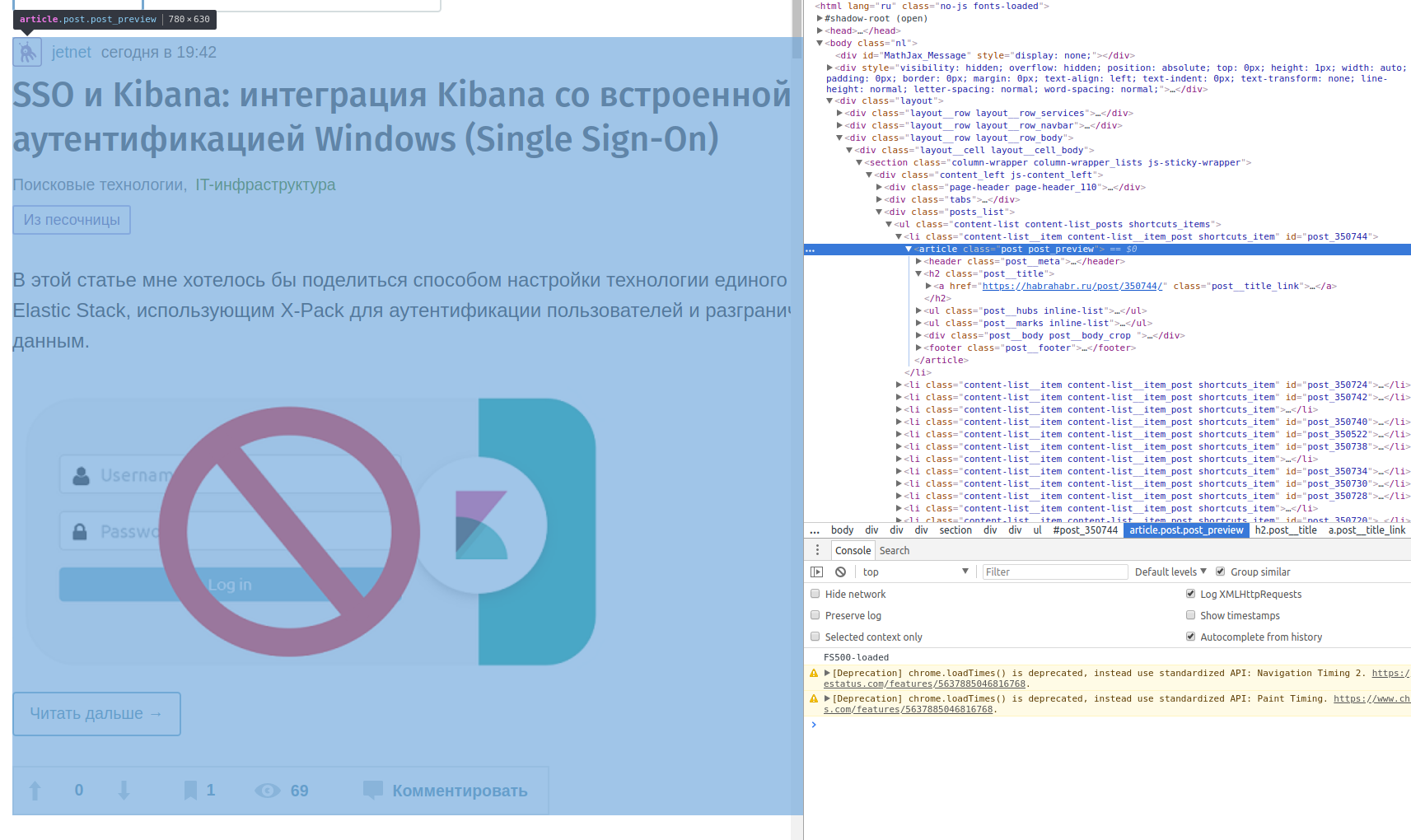
article, у которых в header информация об авторе и дате публикации, а заголовок статьи в теге h2. Все шаги можно покомитно посмотреть в репозитории на github.
Установка и создание проекта 🔗
Для начала установим scrapy. Он тянет довольно много сторонних зависимостей:
$ sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
$ pip install Scrapy
После этого создадим проект:
$ scrapy startproject habr
И ниже он предлагает создать первого паука:
You can start your first spider with:
cd habr
scrapy genspider example example.com
$ cd habr
$ scrapy genspider HabrSpider habrahabr.ru
В итоге в каталоге spiders появился первый алгоритм паука с вот таким содержимым:
import scrapy
class HabrspiderSpider(scrapy.Spider):
name = 'HabrSpider'
allowed_domains = ['habrahabr.ru']
start_urls = ['http://habrahabr.ru/']
def parse(self, response):
pass
У каждого такого паука есть имя, по которому мы будем его запускать, список доменов, на которые можно переходить и стартовый url.
Для запуска перейдём в каталог с scrapy.cfg и выполним scrapy crawl HabrSpider. Предлагаю полностью разобрать вывод, т.к. в нём представлен функционал, который уже идёт “из коробки”. Первым делом - версии пакетов и текущие настройки. По умолчанию Scrapy учитывает файл robots.txt из-за настройки ROBOTSTXT_OBEY:
2018-03-08 23:59:00 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: habr)
2018-03-08 23:59:00 [scrapy.utils.log] INFO: Versions: lxml 4.1.1.0, libxml2 2.9.7, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 17.9.0, Python 3.6.3 (default, Oct 6 2017, 08:44:35) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0g 2 Nov 2017), cryptography 2.1.4, Platform Linux-4.13.0-32-generic-x86_64-with-LinuxMint-18.3-sylvia
2018-03-08 23:59:00 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'habr', 'NEWSPIDER_MODULE': 'habr.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['habr.spiders']}
Во-первых, это расширения, которые вешаются на внутренние события Scrapy и позволяют дополнять поведение по умолчанию. Например, сбор статистики и потребление памяти:
2018-03-08 23:59:00 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage', 'scrapy.extensions.logstats.LogStats']
Во-вторых, список мидлварей, которые обеспечивают некоторые базовые вещи. Делятся на 2 типа: при скачивании и при обходе. Например, RedirectMiddleware выполняет расшифровку редиректов, а RetryMiddleware - повтор запроса в случае окончания таймаута. Вы можете дописать свои для установки JWT токена или эмуляции разных User-Agent, а ненужные - отключить. Кстати, по умолчанию в новом проекте создаётся пустой файл middlewares.py, в котором описаны методы для переопределения.
2018-03-08 23:59:00 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-03-08 23:59:00 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
В-третьих, пайплайны, которые необходимы для обработки данных и модификации их в более удобный формат. Это уже специфичная для каждого проекта вещь, так что по умолчанию тут пустой список.
2018-03-08 23:59:00 [scrapy.middleware] INFO: Enabled item pipelines:
[]
И вот после всех настроек Scrapy наконец запустился:
2018-03-08 23:59:00 [scrapy.core.engine] INFO: Spider opened
2018-03-08 23:59:00 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-03-08 23:59:00 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-03-08 23:59:00 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://habrahabr.ru/robots.txt> from <GET http://habrahabr.ru/robots.txt>
2018-03-08 23:59:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://habrahabr.ru/robots.txt> (referer: None)
2018-03-08 23:59:00 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://habrahabr.ru/> from <GET http://habrahabr.ru/>
2018-03-08 23:59:01 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://habrahabr.ru/> (referer: None)
2018-03-08 23:59:01 [scrapy.core.engine] INFO: Closing spider (finished)
2018-03-08 23:59:01 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 864,
'downloader/request_count': 4,
'downloader/request_method_count/GET': 4,
'downloader/response_bytes': 40689,
'downloader/response_count': 4,
'downloader/response_status_count/200': 2,
'downloader/response_status_count/301': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 3, 8, 20, 59, 1, 168125),
'log_count/DEBUG': 5,
'log_count/INFO': 7,
'memusage/max': 50249728,
'memusage/startup': 50249728,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 3, 8, 20, 59, 0, 161771)}
2018-03-08 23:59:01 [scrapy.core.engine] INFO: Spider closed (finished)
Первым запрашивается robots.txt. Scrapy настолько умный, что следует подсказкам для ботов в этом файле. В данном случае это нам не мешает, но отключить использование можно указав в settings.py ROBOTSTXT_OBEY = False. Я специально обратился к http версии сайта, чтобы показать, что всякие редиректы тоже успешно расшифровываются.
Сохранение результата 🔗
Саму страничку мы как-то получили. Теперь задача вытащить оттуда все данные. Для начала опишем модель того, что нам нужно в файле items.py:
class HabrItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
stars = scrapy.Field()
То есть требуемый csv файл будет состоять из строк такой вот структуры. Проще всего раз получить пример страницы и подобрать соответствующие XPath для данных в response:
$ scrapy-shell https://habrahabr.ru/
$ response.xpath('//div[@class="post post_teaser shortcuts_item"]')
Модифицируем метод parse, чтобы он возвращал именно HabrItem. Для упрощения воспользуемся встроенным классом Selector, хотя не больно-то он и помогает - страдать от XPath всё равно придётся:
def parse(self, response):
root = Selector(response)
# да, классы необходимо указывать полностью
posts = root.xpath('//div[@class="post post_teaser shortcuts_item"]')
for post in posts:
item = HabrItem()
item['title'] = post.xpath('.//a[@class="post__title_link"]/text()').extract()[0]
item['author'] = post.xpath('.//a[@class="post-author__link"]/text()')[1].extract().rstrip()
item['stars'] = post.xpath('.//span[@class="favorite-wjt__counter js-favs_count"]/text()').extract()[0]
yield item
Работа с XPath местами неочевидна и явно выходит за рамки этого материала. В итоге в логах можно видеть что же именно скачалось. Но нам-то это надо видеть в файле, так что посмотрим на pipelines.py. Используется концепция пайплайнов unix - данные передаются из одного объекта в другой, проходя какую-нибудь обработку. Я приведу код сразу целиком, разве что обращу внимание на то, что process_item должен возвращать item для следующего pipeline:
class HabrPipeline(object):
def process_item(self, item, spider):
item['title'] = item['title'].upper()
item['author'] = 'Ув, {}'.format(item['author'])
return item
Зачем так сложно? Почему нельзя сразу в методе parse сохранять результаты? Всё из-за гибкости - здесь нужно разделять способ получения данных от способа обработки, т.к. первый будет переписываться из-за адаптации к структуре сайта. Разработчики любят менять имена стилей, убирать html-элементы, так что данные могут оказаться совсем в другом месте, а то и вовсе подтягиваться ajax-запросами. Так что код, представленный здесь, скорее всего не заработает сразу, а потребует небольшого допиливания.
После подключения HabrPipeline в settings.py и запуска scrapy crawl HabrSpider -o habr.json -t json получаем файл habr.json, в котором содержатся элементы с главной Хабра.
Обрабатываем весь сайт 🔗
Итак, получилось скачать данные для одной страницы. Попробуем адаптировать это на все доступные. Самым примитивным способом было бы прописать их список в start_urls, но это не наш путь :) Для тех, кто работает с Django - не надо искать get_start_urls(), тут существует декларативный подход. Я сменил базовый класс на CrawlSpider, потому что у последнего есть переменная rules, которая используется для генерации списка следующих в очереди на обработку страниц. Проще это показать на примере, а потом объяснить:
import scrapy
from scrapy.selector import Selector
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class HabrSpider(CrawlSpider):
name = "HabrSpider"
allowed_domains = ["habrahabr.ru"]
start_urls = ["https://habrahabr.ru"]
rules = (
Rule(LinkExtractor(allow=('/page\d+/',)), callback='parse_page'),
)
def parse_start_url(self, response):
return self.parse_page(response)
def parse_page(self, response):
root = Selector(response)
# да, классы необходимо указывать полностью
posts = root.xpath('//article[@class="post post_preview"]')
for post in posts:
item = HabrItem()
item['title'] = post.xpath('.//a[@class="post__title_link"]/text()').extract()[0]
item['author'] = post.xpath('.//span[@class="user-info__nickname user-info__nickname_small"]/text()').extract()[0]
item['stars'] = post.xpath('.//span[@class="bookmark__counter js-favs_count"]/text()').extract()[0]
yield item
Паук начинает свою работу с обработки start_urls (скачивании и передачи в parse()), после этого применяются правила для обхода в глубину - на каждой стартовой странице ищутся ссылки, которые описаны в rules и для них применяется callback. Таким образом работа конкретно этого паука будет следующей:
- скачать https://habrahabr.ru
- найти там все ссылки на страницы (регулярка
/page\d+/) - для каждой страницы применить метод parse_item
Авторизация 🔗
Зачастую многие страницы сайта доступны только авторизованным пользователям. Например, список избранного, на выкачивании которого я и предлагаю потренироваться. У Scrapy почему-то нет специального краулера или метода для авторизации, так что есть повод написать собственную миддлварь, в которой будет происходить получение авторизационных кук и патч ими каждого запроса. В самом же пауке переопределён только стартовый url, так что подключим в settings HabrDownloaderMiddleware:
class HabrDownloaderMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
habra_auth = getattr(spider, 'habra_auth', None)
if habra_auth is not None:
key, value = habra_auth
request.cookies[key] = value
return None
def spider_opened(self, spider):
data = {'state': '0d67dc108cbf446f83f8de6b43c8c205', 'consumer': 'habrahabr',
'email': 'email', 'password': 'password'}
response = post('https://id.tmtm.ru/login/', json=data)
cookie = response.headers['set-cookie'].split(';')[0].split('=')
setattr(spider, 'habra_auth', cookie)
spider.logger.info('Spider opened: %s' % spider.name)
Заключение 🔗
Полный код проекта находится в репозитории на github. На этом же простейший паук готов, но это далеко не все возможности фреймворка. Я боюсь их даже перечислять, так что за подробностями отправляю на страницу документации.