Каждый разработчик знает, что если запрос тормозит, то надо просто добавить индекс. Контринтуитивна обратная ситуация - чтобы запрос работал быстрее, надо индекс удалить. Вот именно с таким случаем я и столкнулся на работе.
Попробуем смоделировать ситуацию. У нас есть всего одна таблица, в которой хранится информация по обработанным задачам. Пользователи дёргают ендпоинт, запускается Celery задача, и результат отправляется на email. Ничего сложного, всего несколько столбцов:
- id - уникальный ключ
- task_id - номер задачи
- user_id - кто запустил
- started_at - время начала
- finished_at - время окончания
О хранении исторической информации в реляционной БД
Хочется на фронте клиентам давать статистику - показывать последние 30 завершившихся задач. Запрос будет простым:
SELECT * FROM tasks_log WHERE user_id = %s AND finished_at < now() ORDER BY finished_at DESC LIMIT 30;
Подготовка данных 🔗
Давайте создадим таблицу, чтобы посмотреть планы выполнения. Сразу дисклаймер - у меня не получилось целиком воссоздать проблемную ситуацию. Вероятно из-за того, что таблица на проде очень большая или статистика собрана по другим сэмплам. Однако, посмотреть на различия планов выполнения можно и на тестовых данных.
create table tasks_log (
id serial primary key,
task_id integer not null,
user_id uuid,
started_at timestamp,
finished_at timestamp
);
create index task_log_user_id on tasks_log(user_id);
create index task_log_finished_at on tasks_log(finished_at);
count = 1_000_000
user_ids = random.choices(
[uuid.uuid4() for _ in range(count//10_000)],
weights=[1 for _ in range(count//10_000)],
k=count)
start = datetime.datetime(2000, 1, 1, 0, 0, 0)
rows = []
for i in range(count):
started = start + datetime.timedelta(minutes=i)
rows.append({
'task_id': i,
'user_id': user_ids[i],
'started_at': started,
'finished_at': started + datetime.timedelta(seconds=30),
})
if i % 1000 == 0:
engine.execute(tasks_log.insert(), rows)
rows = []
print(i)
Пока заполняется база, давайте вспомним как устроены индексы. В Postgres их вариантов достаточно много, но тут используется обыкновенный b-tree. Внутри он представляет собой сбалансированное дерево, в листах которого хранятся значения, т.е. поиск будет занимать log(n) - нужно просто спустится по дереву. Причём листы также связаны между собой, что позволяет ходить влево и вправо, если нужен диапазон значений. Гораздо подробнее описано в статье от Postgres Pro, картинка взята оттуда же.
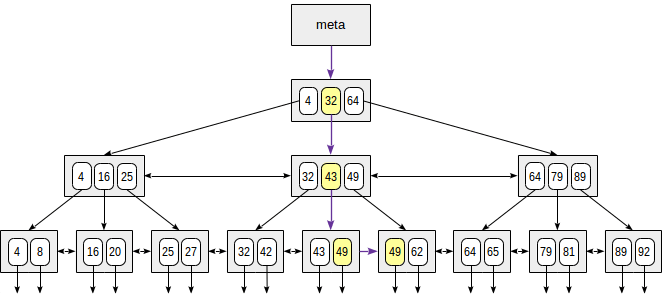
Оптимизация запросов 🔗
У меня сгенерилось 1 000 000 записей, будем экспериментировать на них. Итак, посмотрим на наш основной запрос для существующего пользователя:
EXLPAIN (ANALYZE, buffers on) SELECT * FROM tasks_log WHERE user_id = '734ba89c-7eeb-402a-82e7-70280f98f9fa' AND finished_at < now() ORDER BY finished_at DESC LIMIT 30;
Limit (cost=0.43..107.81 rows=30 width=40) (actual time=0.459..2.408 rows=30 loops=1)
Buffers: shared hit=46
-> Index Scan Backward using task_log_finished_at on tasks_log (cost=0.43..40288.45 rows=11255 width=40) (actual time=0.457..2.397 rows=30 loops=1)
Index Cond: (finished_at < now())
Filter: (user_id = '1bed097e-f74d-411f-8dda-b76f2a707bc7'::uuid)
Rows Removed by Filter: 2783
Buffers: shared hit=46
Planning Time: 0.271 ms
Execution Time: 2.451 ms
Как этот запрос выполнит Postgres? Узлы плана запроса отмечены ->, у нас он один: Index Scan Backward по полю finished_at. Это как Index Scan, только сразу даёт отсортированные строки в порядке убывания. Находим последнюю запись, которая меньше now(), а потом идём по индексу назад, читая строки и отбрасывая не подходящие под условие сравнения с id пользователя. Но что будет, если придётся идти слишком далеко? Возьмём user_id из середины таблицы и выполним тот же запрос:
Limit (cost=0.43..117.89 rows=30 width=40) (actual time=0.159..3.860 rows=30 loops=1)
Buffers: shared hit=71
-> Index Scan Backward using task_log_finished_at on tasks_log (cost=0.43..40288.45 rows=10290 width=40) (actual time=0.157..3.847 rows=30 loops=1)
Index Cond: (finished_at < now())
Filter: (user_id = '738d2938-ae54-4210-99b9-915c1055abd2'::uuid)
Rows Removed by Filter: 4546
Buffers: shared hit=71
Planning Time: 0.377 ms
Execution Time: 3.929 ms
Время выполнения увеличилось почти в 2 раза. За счёт чего? Правильно - за счёт увеличения количества страниц, которые были подняты с диска (buffers). В первом случае их было 46, во втором уже 71. Здесь первое узкое место - на небольшой базе с одним пользователем весь индекс находится в памяти, и запрос работает очень быстро. На проде же эти страницы могут вымываться из кеша, и тогда вместо hit=71 можно будет видеть что-нибудь типа hit=11 read=60, а любое чтение с диска очень медленное.
Но что будет, если заданного user_id нет в таблице? Postgres будет читать весь индекс? Давайте проверим! Оп, и у нас уже совсем другой план выполнения:
Limit (cost=8.46..8.46 rows=1 width=40) (actual time=0.039..0.041 rows=0 loops=1)
Buffers: shared hit=3
-> Sort (cost=8.46..8.46 rows=1 width=40) (actual time=0.036..0.037 rows=0 loops=1)
Sort Key: finished_at DESC
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=3
-> Index Scan using tasks_log_user_id on tasks_log (cost=0.42..8.45 rows=1 width=40) (actual time=0.022..0.023 rows=0 loops=1)
Index Cond: (user_id = '1bed097e-f74d-411f-8dda-b76f2a707bc0'::uuid)
Filter: (finished_at < now())
Buffers: shared hit=3
Planning Time: 0.402 ms
Execution Time: 0.088 ms
Здесь используется индекс по user_id, выбираются все записи и сортируются в памяти. Т.к. Index Scan ничего не нашёл, то и сортировать нечего, так что запрос выполняется очень быстро. Важный вопрос - почему сменился план выполнения? Вероятно потому, что пройтись по tasks_log_user_id достаточно дёшево (всего 3 страницы). Почему бы сначала не узнать есть ли вообще записи для такого пользователя, это может сэкономить время. И здесь может быть вторая опасность - что если проверить наличие записей будет дорого? Как выяснилось, планировщик просто не будет его выполнять. Собственно, это и случилось в проде - на любой запрос выполнялся Index Scan Backward, что на больших объёмах данных приводил к большому чтению с диска.
Решение 🔗
После такого ресёрча стало понятно, что Index Scan Backward на больших объёмах данных с дополнительным фильтром по user_id работает не эффективно. Возможны 2 варианта:
- Улучшить индекс. Например, сделать составной (user_id, finished_at desc).
- Удалить индекс по finished_at и всегда выбирать записи по пользователю и сортировать в памяти.
В первом варианте для худшего случая план выполнения станет таким:
Limit (cost=0.43..79.01 rows=30 width=40) (actual time=0.168..0.278 rows=30 loops=1)
Buffers: shared hit=23 read=2
-> Index Scan using finished_at_user_id on tasks_log (cost=0.43..26954.06 rows=10290 width=40) (actual time=0.166..0.261 rows=30 loops=1)
Index Cond: ((user_id = '738d2938-ae54-4210-99b9-915c1055abd2'::uuid) AND (finished_at < now()))
Buffers: shared hit=23 read=2
Planning Time: 0.375 ms
Execution Time: 0.351 ms
Что гораздо лучше, чем ~4ms до этого.
Выводы 🔗
Хоть в Postgres принципиально нельзя вмешиваться в работу планировщика и добавлять подсказки какой индекс использовать, тем не менее можно оптимизировать запросы косвенными путями. Главное - внимательно читать план выполнения. Слоник - он умный!